Creating an Efficient Decision Tree in Java
Creating an Efficient Decision Tree in Java
Background
At Staples SparX we often deal with two major challenges. We want to create highly accurate data models based on the insights gleaned from machine learning. And we want to be able to evaluate these models efficiently at runtime. Currently we observe a 10 millisecond timeout when calling our modeling web service.
In order to make the most accurate predictions possible, our data scientists experiment with a number of different modeling techniques. Some of them (ex: linear or logistic regression) are quite computationally cheap to score. Additionally, models such as those have a number of rich, native libraries that can be used to achieve impressive speedups. Particularly if the nature of the algorithm allows vectorization.
However, our data scientists have found great success with decision tree based models. Both with single trees and models involving an ensemble of trees (such as gradient boosted trees).
Some of these trees are quite large and are computationally expensive to evaluate.
Problem
So lets define our problem:
- One of our data scientists trained a GBM model with 900 trees and a total of 522k nodes.
- Our modeling web service has an SLA of 10 milliseconds.
- Our web services are written in Clojure, so it must run on the JVM.
- We would like to be able to score this model at minimum 15 times per call. Preferably more as each additional prediction provides value.
Setup
All of the testing for this article was performed on a Late 2013 MacBook Pro Retina 15-inch with a 2.3 GHz Intel Core i7 processor. The JDK version was HotSpot(TM) 64-Bit Server VM - build 25.40-b25. Benchmarking was completed with JMH version 1.7
Base Implementation
The first step is to produce a tree representation that we will use for our GBM model. At SparX, we have produced a library for this purpose: Sequoia.
Sequoia is written in Java for performance reasons. I had done some work on implementing it in Clojure. However, I abandoned that work for the Java version.
While possible to directly use primitive arrays in Clojure, it feels slightly unnatural to me. Additionally, I found it easier to write Sequoia’s tree searching and pruning algorithms in an imperative style.
The base class is a Node. A Node has a value, a flag indicating if it is a leaf, offsets to its children, and a condition to determine which child comes next.
A tree is just an array of nodes. However, for this problem we will not use the tree class, as we are dealing with an ensemble of trees.
A forest is an array of nodes and an array of roots.
Traversing the forest is quite simple. For each logical tree we start at the root and evaluate the node’s condition. The condition returns the offset for the next node. We continue traversing the tree until hitting a leaf node. That node’s value is the tree’s score.
I took the GBM model trained by our data scientist and loaded it into this tree representation. The model was trained using scikit-learn. Every node has a numeric condition and two children. So all of the nodes use the following condition.
We store our features in a Object2DoubleMap from the fastutil library. This is to attempt to avoid the cost of boxing and unboxing features.
So our forest is parameterized as:
Using JMH to benchmark our evaluation, we produce the following number:
342.810 ±(99.9%) 1.743 us/op [Average]
That number is alright. But if our target is 15 evaluations, pretty quickly we’re halfway to our SLA on average. And that is just evaluating the model.
One caveat is that the benchmark was ran on my laptop. And the servers we use are obviously faster than that. But it’s still clear that we need some improvement.
Removing Hash Lookups
So I ran our tree in a profiler (YourKit) to check for hotspots that could be optimized. Right away we immediately see an area to improve.
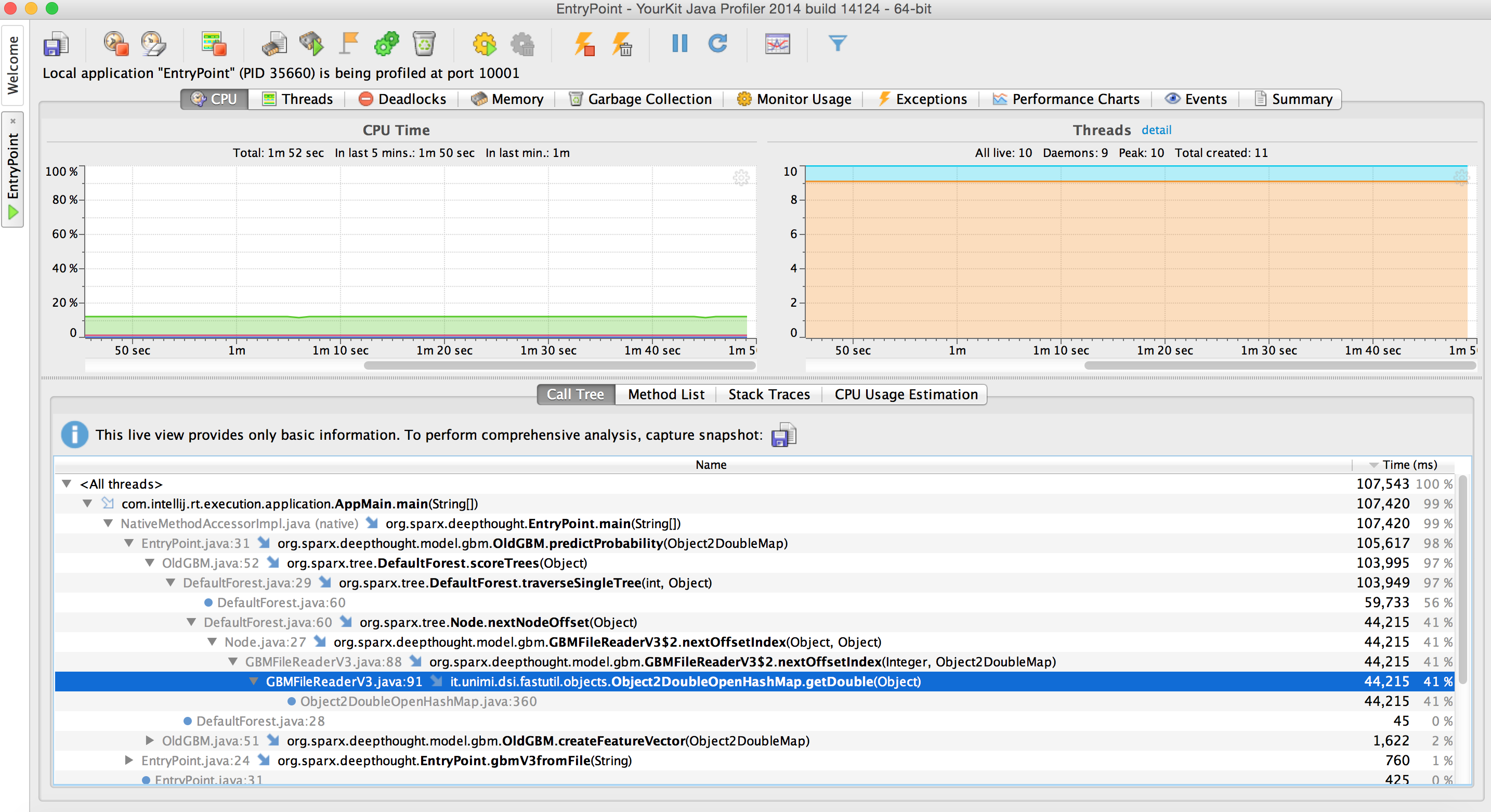
It looks like despite my good faith attempts to optimize feature lookup by using an Object2DoubleMap, feature lookup is still taking 41% of the CPU time. This is believable as we have to calculate a hashcode at every branch node we visit.
So lets replace those maps with arrays. I will now pass a double array to the Forest. And features will be looked up by using array indices. My forest now is parameterized as Forest<Integer, double[]>.
Using JMH again:
236.070 ±(99.9%) 1.133 us/op [Average]
Boom. That’s a pretty solid speedup for what was a small change.
Removing Pointer Chasing
But can we do better? To the profiler!
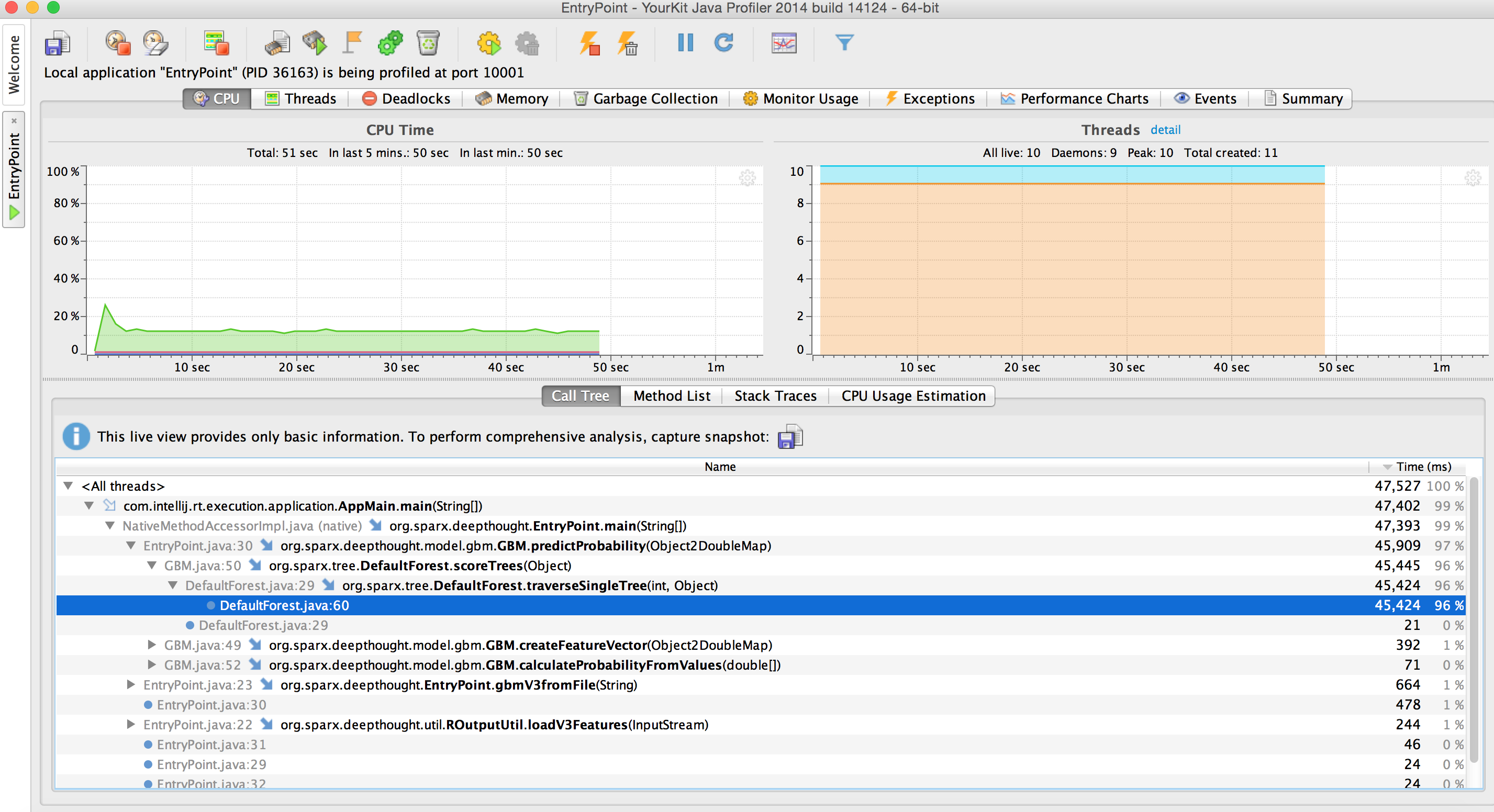
Wow that’s pretty unhelpful. We see a startling number: 96%. But upon further inspection, that is just pointing to the traverseSingleTree loop. It seems pretty intuitive that most of our time should be spent iterating through the 522k nodes.
So in order to achieve further speedups we need to consider how to most efficiently iterate through those nodes. And the performance of iterating through nodes depends on how trees are represented in memory.
The forest is represented as an array of Node objects. So our forest is an array of Objects. And because we are dealing with the JVM, that means our forest is actually an array of Object references. So it seems like addressing pointer chasing is our next big speedup.
In the future, working around this performance issue may not be necessary. Proposals such as Project Valhalla and ObjectLayout could alleviate pointer chasing in future JDK versions. In the meantime however, different work arounds must be found to improve memory access performance.
One way to avoid object references is to split our forest into multiple primitive arrays. This is a workable solution that comes at the expense of expressiveness. My previous tree could have different conditions for different nodes. The new tree can only have one condition (to avoid pointer chasing on an array of Condition objects). This works in my case, as all of the nodes use numeric conditions based upon a cutpoint.
So I created a specialized Forest implementation called DoubleForest:
For ease of use, this forest can be constructed from the original forest:
The forest pretty much is a group of primitive areas containing the data formerly held by Node objects. Additionally, scoring the forest follows the same process. Traverse the tree until a leaf node is encountered.
Using JMH again:
162.488 ±(99.9%) 0.495 us/op [Average]
Not bad at all. That is a 2.1X speedup from where we started. Definitely a solid improvement.
I think that this is a good stopping point for this post. 162 microseconds per evaluation allows us to comfortably meet our SLA.
Future
Decision trees are a big part of our modeling at SparX so there is some more work that I have completed that can be saved for future posts.
Other things that I have explored:
- representing the condition object in different ways to for best performance.
- using Unsafe to create offheap structs opposed to the primitive array strategy.
- using pruning algorithms to avoid unnecessary work.
In the meantime I encourage you to take a look at the Sequoia library. There is definitely work that needs to be done to make it more usable as an open source library: stabilized api, documentation, readme, etc. However, if you have a need for an efficient decision tree implementation you might find it useful. At SparX, we have been using it in production successfully for almost a year.